CUDA转HIP编译指导安装教程
1. 选择HIP 的原因
HIP是C++运行时API和内核语言,允许开发人员从单个源代码为AMD和NVIDIA GPU创建可移植的应用程序。
1.1 特征
HIP允许开发人员将CUDA代码转换为便携式C++。同样的源代码可以编译运行在NVIDIA或AMD GPU上。主要特征包括:
(1) HIP非常精炼,对CUDA或hcc“HC”模式下直接编码的性能影响很小或没有影响。
(2) HIP允许在单一源代码C++语言中编写编码,包括模板、C++ 11 LAMBDAS、类、命名空间等功能。
(3) HIP允许开发人员在每个目标平台上使用“最佳”的开发环境和工具。
(4) “hipify”工具自动将源代码从CUDA转换为HIP。
(5) 开发人员可以专门为平台(CUDA或hcc)调整性能或处理棘手的情况。新项目可以直接在便携式HIP C++语言中开,可以在NVIDIA或AMD平台上运行。此外,HIP还提供了移植工具,可以方便地将现有的CUDA代码移植到HIP层,与原来的CUDA应用程序相比,不会损失性能。HIP并不是CUDA的替代品,开发人员应该做一些手动编码和性能调整工作来完成这个端口。
1.2 接入HIP
在GitHub中,HIP是开源的,存储库维护以下分支。
(1) 主分支:这是一个稳定的分支,并与最新的发布分支一起更新。例如,如果最新的HIP版本是rocm-4.1.x,则主存储库将基于此版本。
(2) 次分支:次分支对应于包含释放标记的每个ROCM次分支,例如rocm-4.0.x、rocm-4.1.x和其他。HIP版本包括为每个ROCM版本命名规则约定,以帮助区分它们。例如,rocmx.yy,其中x.yy反映了ROCm的发布号。
1.3 HIP 可移植性和编译器技术
可以用AMD或NVIDIA GPU编译HIPC代码。 在AMD ROCm平台上,HIP提供了一个基于HIP-Clang编译器的头库和运行时库。 HIP运行时实现HIP流、事件和内存API,并且是与应用程序链接的对象库。
在NVIDIA CUDA平台上,HIP提供了一个头文件,它从HIP运行时API转换为CUDA运行时API。 头文件主要包含内联函数,因此,在HIP中编码的开销非常低,开发人员应该期望与在本机CUDA中编码的性能相同。 然后用nvcc编译代码,这是CUDASDK提供的标准C编译器。 开发人员可以使用CUDA SDK支持的任何工具,包括CUDA分析器和调试器。
因此,HIP为任何一个平台都提供了源代码的可移植性。HIP提供了硬件编译器驱动程序,它将根据所需的平台调用适当的工具链。所有头的源代码和库都可以在github上实现。
2. 编译样例
2.1 kernel 样例
以kernel 程序为例,该程序主要是通过调用核函数,把NVIDIA显卡透传到虚拟机内部,然后使用CUDA平台进行GPU运算的实践。原程序的cu代码如下:
#include <iostream>
#include <math.h>
// 添加两个数组元素的核函数
__global__
void add(int n, float *x, float *y)
{
int index = threadIdx.x;
int stride = blockDim.x;
for (int i = index; i < n; i += stride)
y[i] = x[i] + y[i];
}
int main(void)
{
int N = 1<<20;
float *x, *y;
// 分配统一内存–可从CPU或GPU访问
cudaMallocManaged(&x, N*sizeof(float));
cudaMallocManaged(&y, N*sizeof(float));
// 在主机上初始化x 和y阵列
for (int i = 0; i < N; i++) {
x[i] = 1.0f;
y[i] = 2.0f;
}
//在GPU上的1M元素上运行内核
add<<<1, 256>>>(N, x, y);
// 在主机上访问之前,等待GPU完成操作
cudaDeviceSynchronize();
//检查错误(所有值应为3.0f)
float maxError = 0.0f;
for (int i = 0; i < N; i++)
maxError = fmax(maxError, fabs(y[i]-3.0f));
std::cout << "Max error: " << maxError << std::endl;
// 释放内存
cudaFree(x);
cudaFree(y);
return 0;
}
(1) 在系统中提交作业: 由于原程序是kernel.cu,需要对程序进行编译,运行命令:
hipify-perl kernel.cu >new_kernel.cpp

(2) 打开new_kernel.cpp。
#include "hip/hip_runtime.h"
#include <iostream>
#include <math.h>
// 添加两个数组元素的核函数
__global__
void add(int n, float *x, float *y)
{
int index = threadIdx.x;
int stride = blockDim.x;
for (int i = index; i < n; i += stride)
y[i] = x[i] + y[i];
}
int main(void)
{
int N = 1<<20;
float *x, *y;
// 分配统一内存–可从CPU或GPU访问
hipMallocManaged(&x, N*sizeof(float));
hipMallocManaged(&y, N*sizeof(float));
// 在主机上初始化x 和y阵列
for (int i = 0; i < N; i++) {
x[i] = 1.0f;
y[i] = 2.0f;
}
// 在GPU上的1M元素上运行内核
hipLaunchKernelGGL(add, dim3(1), dim3(256), 0, 0, N, x, y);
// 在主机上访问之前,等待GPU完成操作
hipDeviceSynchronize();
// 检查错误(所有值应为3.0f)
float maxError = 0.0f;
for (int i = 0; i < N; i++)
maxError = fmax(maxError, fabs(y[i]-3.0f));
std::cout << "Max error: " << maxError << std::endl;
// 释放内存
hipFree(x);
hipFree(y);
return 0;
}
(3) 可以看到原kernel 程序大部分已经进行了编译,检查这个程序,将无法进行编译的代码进行手动编译,之后再次提交作业。
/opt/rocm/hip/bin/hipcc new_kernel.o -o new_kernel
./new_kernel
Max error:0
rm -f ./new_kernel
rm -f new_kernel.o
(4) 程序可以正常运行,编译完成。
2.2 Runtime样例
以Runtime.cu为例,这个程序的定义带有了global这个标签,表示程序 是在GPU上运行,除了常规的参数之外,还增加了<<<>>>修饰,<<<1,array_size>>>表示使用一个线程块,使用ARRAY_SIZE进行线程处理。
__global__ void square(float* d_out,float* d_in){
int idx = threadIdx.x;
float f = d_in[idx];
d_out[idx] = f * f;
}
int main(int argc,char** argv){
const int ARRAY_SIZE = 8;
const int ARRAY_BYTES = ARRAY_SIZE * sizeof(float);
// 在主机上生成输入数组
float h_in[ARRAY_SIZE];
for(int i=0;i<ARRAY_SIZE;i++){
h_in[i] = float(i);
}
float h_out[ARRAY_SIZE];
// 声明GPU内存指针
float* d_in;
float* d_out;
// 分配GPU内存
cudaMalloc((void**) &d_in,ARRAY_BYTES);
cudaMalloc((void**) &d_out,ARRAY_BYTES);
// 将数组传输到GPU
cudaMemcpy(d_in,h_in,ARRAY_BYTES,cudaMemcpyHostToDevice);
// 启动内核
square<<<1,ARRAY_SIZE>>>(d_out,d_in);
// 将结果复制回GPU
cudaMemcpy(h_out,d_out,ARRAY_BYTES,cudaMemcpyDeviceToHost);
// 将结果打印出来
for(int i=0;i<ARRAY_SIZE;i++){
printf("%f",h_out[i]);
printf(((i%4) != 3) ? "\t" : "\n");
}
// 空闲GPU内存分配
cudaFree(d_in);
cudaFree(d_out);
return 0;
}
(1) 同理,由于未经过编译,在系统中提交作业同样会报错。
(2) 对程序进行编译,运行hipify-perl Runtime.cu > new_Runtime.cpp,得到新的cpp 文件。

(3) 打开cpp文件。
__global__ void square(float* d_out,float* d_in){
int idx = threadIdx.x;
float f = d_in[idx];
d_out[idx] = f * f;
}
int main(int argc,char** argv){
const int ARRAY_SIZE = 8;
const int ARRAY_BYTES = ARRAY_SIZE * sizeof(float);
//在主机上生成输入数组
float h_in[ARRAY_SIZE];
for(int i=0;i<ARRAY_SIZE;i++){
h_in[i] = float(i);
}
float h_out[ARRAY_SIZE];
// 声明GPU内存指针
float* d_in;
float* d_out;
// 分配GPU内存
hipMalloc((void**) &d_in,ARRAY_BYTES);
hipMalloc((void**) &d_out,ARRAY_BYTES);
// 将数组传输到GPU
hipMemcpy(d_in,h_in,ARRAY_BYTES,hipMemcpyHostToDevice);
// 启动内核
hipLaunchKernelGGL(square, dim3(1), dim3(ARRAY_SIZE), 0, 0, d_out,d_in);
// 将结果复制回GPU
hipMemcpy(h_out,d_out,ARRAY_BYTES,hipMemcpyDeviceToHost);
// 将结果打印出来
for(int i=0;i<ARRAY_SIZE;i++){
printf("%f",h_out[i]);
printf(((i%4) != 3) ? "\t" : "\n");
}
// 空闲GPU内存分配
hipFree(d_in);
hipFree(d_out);
return 0;
}
(4) 检查这个程序,将无法进行编译的代码进行手动编译,之后再次提交作业:
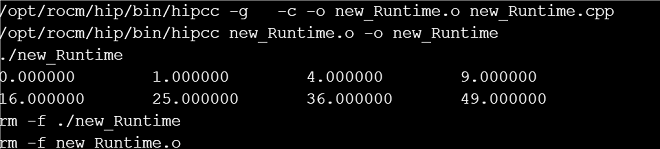
可以看到,系统可以正常运行GPU程序,编译完成。
3. CUDA 转HIP 系统说明
3.1 编译工具HIPIFY
下面是一个简单的测试,它展示了如何使用hipify-Perl 将CUDA代码移植到HIP。这个例子很简单,不需要手动修改hipified源代码-只需hipify和编译:
(1) 将hip/bin 路径添加到PATH。
export PATH=$PATH:[MYHIP]/bin
(2) 定义环境变量。
export HIP_PATH=[MYHIP]
(3) 生成一个可执行文件。
$ cd ~/hip/samples/0_Intro/square
$ make
/home/user/hip/bin/hipify-perl square.cu > square.cpp
/home/user/hip/bin/hipcc square.cpp -o square.out
/home/user/hip/bin/hipcc -use-staticlib square.cpp -o square.out.static
(4) 执行文件。
$ ./square.out
info: running on device Vega20 [Radeon Pro W5500]
info: allocate host mem ( 7.63 MB)
info: allocate device mem ( 7.63 MB)
info: copy Host2Device
info: launch 'vector_square' kernel
info: copy Device2Host
info: check result
PASSED!
3.2 HIP 端口处理过程
移植一个新的CUDA 项目:
(1) 在CUDA机器上启动端口通常是最简单的方法,因为您可以将代码片段增量地移植到HIP,同时将其余部分留在CUDA中。(回想一下,在CUDA机器上,HIP只是CUDA上的一个很小的部分,因此这两种代码类型可以在NVCC平台上互操作。)此外,HIP端口可以与原始CUDA代码进行功能和性能的比较。
(2) 一旦CUDA代码被移植到HIP中并在CUDA 机器上运行,请使用AMD机器上的HIP编译器来编译HIP代码。
(3) HIP端口可以取代CUDA版本:HIP可以提供与本地CUDA实现相同的性能,具有英伟达和AMD架构的可移植性,以及未来C标准支持的路径。您可以通过条件编译或将它们添加到开源HIP基础设施中来处理特定于平台的功能。
(4) 使用bin/hipconvertinplace-perl.sh对CUDA源目录中的所有代码文件进行hipify。