SLURM调度器使用教程
1 介绍
将⾼性能计算平台的计算资源合理⾼效分配给⽤户应⽤程序,是平台运⾏的基本⽬标也是⽤户使⽤的基本技能。SLURM作为⼀款开源、模块化、可拓展的资源管理器,⾃2001年发布以来不断发展壮⼤,⽬前全球排名TOP500的超级计算机中有约70%使⽤SLURM。
SLURM (Simple Linux Utility for Resource Management)是⼀种可⽤于⼤型计算节点集群的⾼度可伸缩和容错的集群管理器和作业调度系统,被世界范围内的超级计算机和计算集群⼴泛采⽤。SLURM 维护着⼀个待处理⼯作的队列并管理此⼯作的整体资源利⽤。它以⼀种共享或⾮共享的⽅式管理可⽤的计算节点(取决于资源的需求),以供⽤户执⾏⼯作。SLURM 会为任务队列合理地分配资源,并监视作业⾄其完成。如今,SLURM 已经成为了很多最强⼤的超级计算机上使⽤的领先资源管理器,如天河⼆号上便使⽤了 SLURM 资源管理系统。
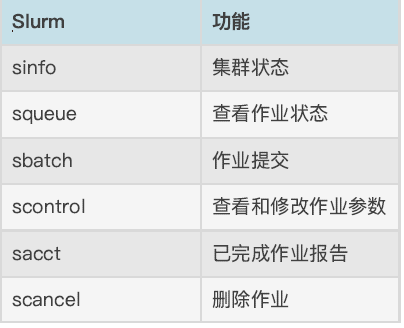
2 Slurm常用命令
2.1 sinfo命令:查看集群状态
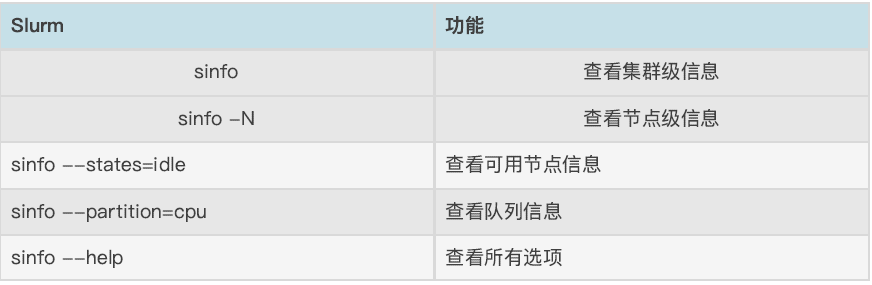
节点状态包括:
drain(节点故障), alloc (节点完全占⽤), idle (节点可⽤), down (节点下线), mix (节点部分占⽤,但仍有剩余资源)。
2.2 squeue命令:查看作业信息
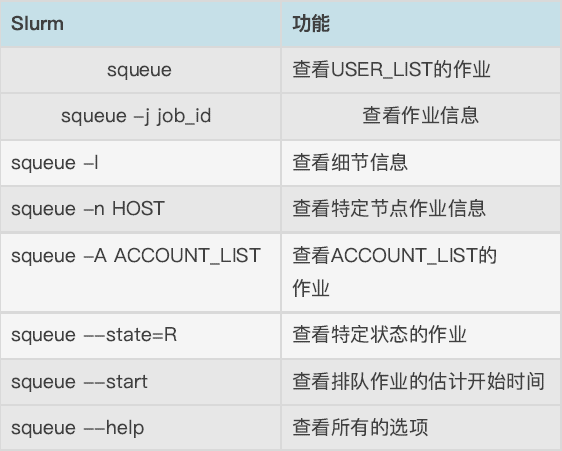
作业状态包括:
R (正在运⾏), PD (正在排队), CG (即将完成), CD (已完成)。
Tips:默认情况下, squeue 只会展示您⾃⼰账户下在排队或在运⾏的作业。
sbatch命令:作业提交
准备作业脚本然后通过 sbatch 提交是 Slurm 的最常⻅⽤法,⼀般的命令格式为:
sbatch jobscript.sh
2.3 Slurm 参数集
Slurm 具有丰富的参数集, 以下是最常⽤的参数:

这是⼀个名为 cpu.slurm 的作业脚本,该脚本向node队列申请1个节点56核,将walltime限制设置为10秒,在此作业中执⾏的命令是 /bin/hostname 。
#!/bin/bash
#SBATCH --job-name=hostname
#SBATCH --partition=node
#SBATCH -N 1
#SBATCH -n 56
#SBATCH --output=%j.out
#SBATCH --error=%j.err
#SBATCH --time=00:00:10
#SBATCH --exclusive
/bin/hostname
2.4 scontrol命令:查看和修改作业参数
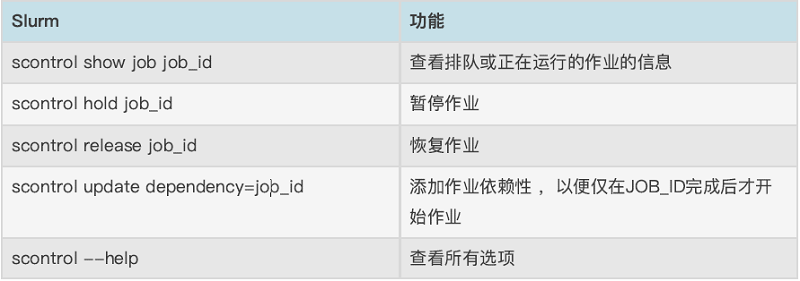
2.5 sacct命令:查看历史作业
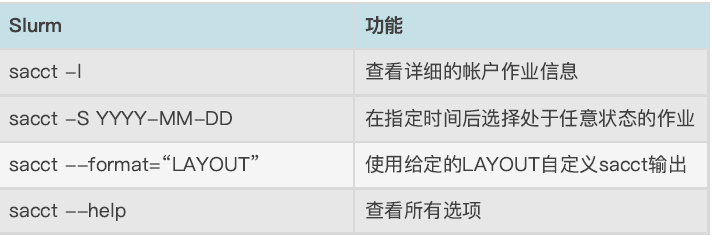
Tips:默认情况下,sacct显示过去 24⼩时的账号作业信息。
2.6 Slurm环境变量
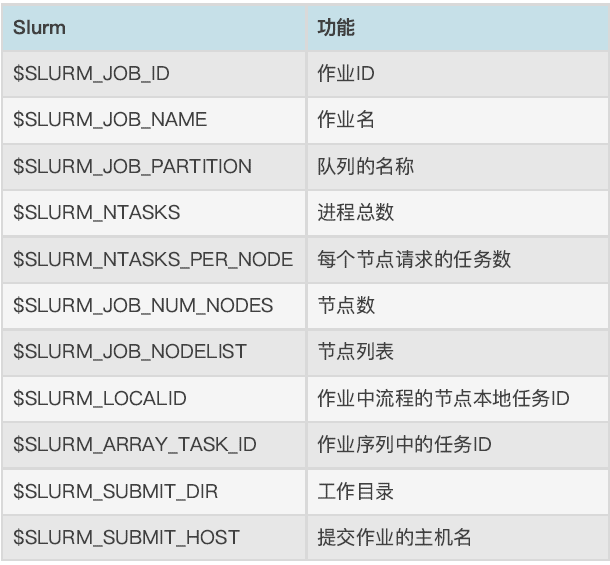
Tips:将作业脚本中的命令⾏改为env,提交作业,可打印Slrum所有环境变量。
3 Q&A
(1) Question1:为什么提交了作业,但作业没运⾏?
答:作业是否正常运⾏取决于⽤户申请的资源情况和当前系统的情况。提交作业后可使⽤squeue 命令来查看作业情况。所展示的最后⼀列(NODELIST(REASON) )需要关注。当作业在运⾏时,显示作业所运⾏的计算节点;当作业未运⾏时,则显示未运⾏的原因,常⻅的原因,如下表所示。
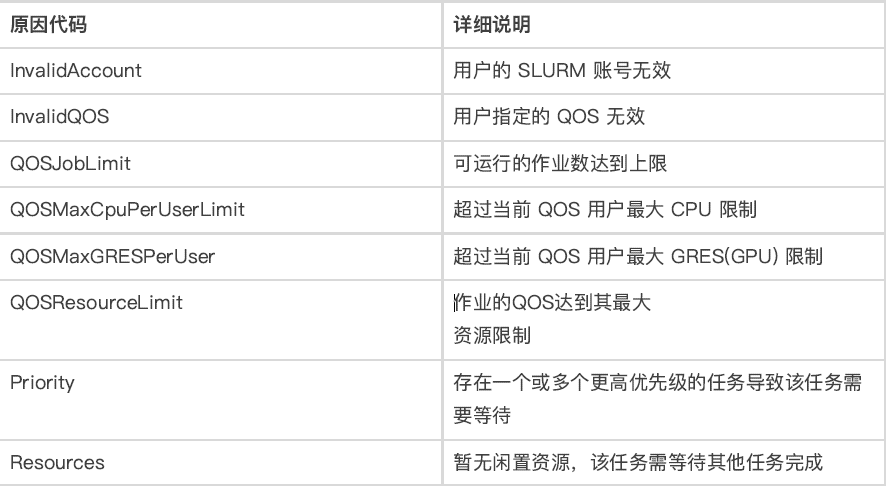
Tips: ⽤户申请的资源超过⾃⼰所在的QOS限制时,SLURM 会直接拒绝该任务。⽤户可登录平台管理系统查看⾃⼰资源权限,也可通过shell终端利⽤如下命令查看⾃⼰的资源权限:/share/user_bin/check_limit.sh
(2) Question2:提交GPU任务,已经在GPU节点上排队了,发现申请的GPU卡数不对,想调整但⼜不想取消任务重新提交怎么办?
答:可使⽤scontrol update jobid=job_id命令更新任务,具体为:scontrol update jobid=job_id partition=gpu gres=gpu:*