曙光智算计算服务人工智能深度学习平台普通用户使用手册
使用方法一:SothisAI方法
SothisAI是一种可以直观、快速地领略深度学习魅力的方式。它的本质在于创建docker镜像,并在镜像环境内快速启动程序,训练、调优、推理,不需要输入代码,只需要动动鼠标,是一种新手友好的方式。但对于老手来说,我们更推荐方法二、方法三。因为其更高的灵活度,以及比镜像更快的速度。
1 TensorFlow深度学习框架
进入曙光智算平台页面,在首页(概览)下拉查看“我的服务”,点击“智能计算服务”;选择平台内置镜像,点击“Tensorflow”模块。TensorFlow模块支持训练、调优、推理三种任务。

1.1 TensorFlow训练任务
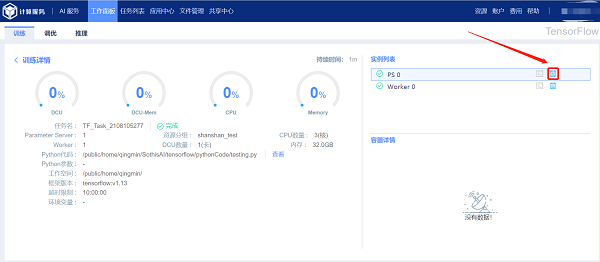
进入TensorFlow 模块,默认访问TensorFlow 的训练任务页面,如图所示:

训练任务的提交方式支持分布式提交、非分布式提交两种提交方式。
1.1.1 提交分布式任务
如图所示,创建分布式TensorFlow 训练任务时的所需参数包括:

(1) Python 代码:表示训练所需要的python 程序的路径地址,支持手动输入、集群文件选取、和本地文件上传等三种输入方式,可以点击“预览”按钮预览选中的python 程序;
(2) Python 参数:表示python 代码所需要的参数;
(3) 工作空间:表示python 程序执行时所在的工作目录,可以通过右边的文件夹浏览按钮选择工作空间的地址;
(4) 框架版本:表示用来进行训练的TensorFlow 镜像版本;
(5) TB 日志路径:表示用于TensorBoard 的日志文件输出目录,可以通过右边的文件夹浏览按钮选择生成日志所在的文件夹;(选填)
(6) 环境变量:表示训练过程中所需要的环境变量,可以通过右边的文件浏览按钮、文件上传按钮进行环境变量文件的集群选取和本地上传;(选填)
(7) 任务类型:表示训练任务的提交方式,提交分布式任务选中“分布式”;
(8) 实现方式:选择分布式训练使用的框架;
(9) 资源分组:表示任务使用的节点名称;
(10) Parameter Server:表示参数服务器节点的数量,下拉框显示更多选项;
(11) Worker:表示计算节点的数量。
(12) CPU 数量:表示一个Parameter Server 或Worker 占用的CPU 数量;
(13) DCU 数量:表示一个Parameter Server 或Worker 占用的DCU(GPU) 数量;
(14) 内存:表示一个Worker 占用的内存大小;
(15) 超时限制:表示该训练任务被强制停止的时间阈值。
最后,输入相关参数,点击“运行”按钮进入训练任务的详情页面。
1.1.1.1 创建数据集
通过“E-File“方式将数据集上传到用户账户下的SothisAI路径下:
/public/home/username/SothisAI/tensorflow/pythonCode
1.1.1.2 选取集群文件
以“Python Code”为例:点击“浏览文件”按钮弹出文件选择器,在文件选择器中选中需要使用python 代码文件“mnist_dist.py”,点击“确认”按钮确认完成文件选取。
1.1.1.3 上传本地文件
以“Python Code”为例:
点击文件上传按钮弹出文件选择器,在文件选择器中选中需要使用的python 代码文件“mnist_dist.py”,点击“打开”按钮开始上传文件,文件上传成功后输入框自动填充文件保存目录。
【注意】Python Code 只支持上传以“.py”为后缀的文件,文件大小超过20MB 建议使用E-File先上传至个人目录,或者使用WinSCP(一个Windows环境下使用SSH的开源图形化SFTP客户端)上传。
1.1.1.4 预览python代码
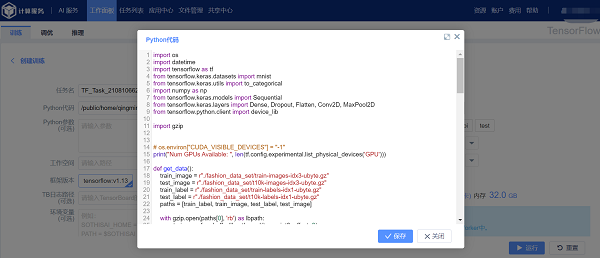
在Python 代码输入框中填写python 代码所在的地址(也可通过文件集群选取或本地上传进行自动填充)后,点击预览按钮预览python 代码。
1.1.2 提交非分布式任务

如图所示,创建非分布式TensorFlow 训练任务提交相对简单,参数与分布式任务基本相同,请参照1.1.1章节。不同参数包括:
(1) 任务类型:表示训练任务的提交方式,提交非分布式任务选中“非分布式”;
(2) 框架版本:可选的Tesorflow版本,没有想要的建议E-Shell中配置个人环境;
(3) 资源分组:表示任务使用的节点名称;
(4) CPU 数量:表示训练任务占用的CPU 数量;
(5) DCU 数量:表示训练任务占用的DCU 数量;
(6) 内存:表示训练任务占用的内存大小;
(7) 超时限制:任务被强行停止的时长阈值。
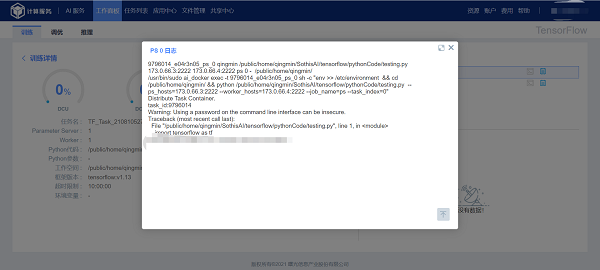
1.1.3 查看容器日志
1.2 TensorFlow调优任务
1.2.1 创建任务
点击“创建调优任务”进入TensorFlow 调优任务创建页面, 调优任务默认以分布式的方式执行。
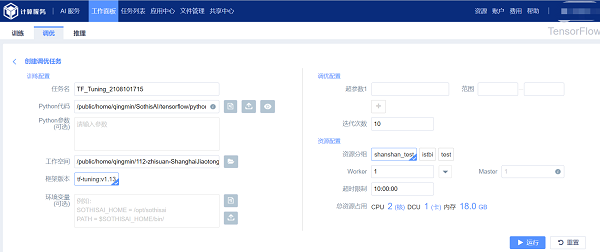
创建TensorFlow 调优任务时的所需参数包括:
(1) 任务名:表示该任务的名称且不允许重复;
(2) Python 代码:表示调优任务所需要的python 程序的路径地址,支持手动输入、集群文件选取、和本地文件上传等三种输入方式,可以点击“预览”按钮预览选中的python 程序(参考1.1.1.2-1.1.1.4节);
(3) Python 参数:表示python 代码所需要的参数;(选填)
(4) 工作空间:表示python 程序执行时所在的工作目录,可以通过右边的文件夹浏览按钮选择工作空间的地址;
(5) 框架版本:表示用来进行调优任务的TensorFlow 镜像版本;
(6) 环境变量:表示调优任务执行过程中所需要的环境变量,可以通过右边的文件浏览按钮选择加载环境变量的sh文件(可选);
(7) 上传按钮进行环境变量文件的集群选取和本地上传(可选);
(8) 超参数名称:调优针对的超参数(最多同时支持5 个超参数);
(9) 超参数范围:待调优的超参数的调优范围;
(10) 资源分组:当下可用的队列名;
(11) Master:表示负责发布、统计迭代次数和数据记录的管理节点数量,任务量小,默认为1;
(12) Worker:表示工作节点的数量;
(13) CPU数量:表示一个Worker 占用的CPU 数量;
(14) DCU数量:表示一个Worker 占用的DCU(GPU) 数量;
(15) 内存:表示一个Worker 占用的内存大小;
(16) 超时限制:该任务强制停止的时间阈值。
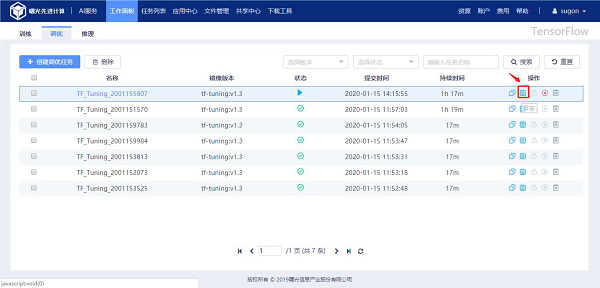
1.2.2 查看任务日志
2 Caffe深度学习框架
Caffe 深度学习框架提交作业包括四个环节:数据集、模型、训练以及推理。目前仅支持“图像分类”任务,以供使用者快速领略深度学习的魅力。
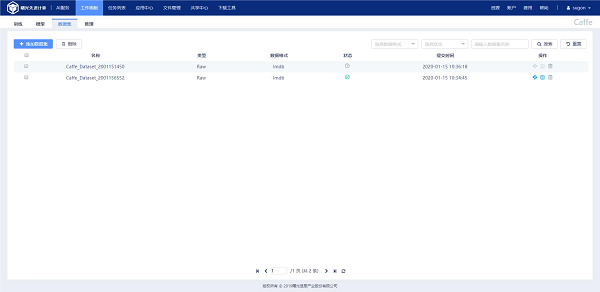
2.1 Caffe数据集
通过点击“添加数据集”按钮,进入创建数据集页面,该页面支持“Raw(原始数据集)”、“Processed(预处理后数据集)”两种创建方式.
2.1.1 创建Raw 数据集

Raw数据集是指未经过工具转换为lmdb、leveldb格式的数据集。
相关参数如下:
(1) 数据集名称:数据集名称,不允许重复;
(2) 训练数据集:表示训练样本集,点击 按钮选择训练样本集所在的文件夹;
(3) 测试数据集:表示测试样本集,点击 按钮选择验证样本集所在的文件夹;
(4) 训练标签:标签信息所储存的文件,点击 按钮选择文件;
(5) 测试标签:标签信息所储存的文件,点击 按钮选择文件;
(6) 图像尺寸:数据集中的图片需要被Resize/Reshape成的尺寸;
(7) 图像类型:支持“jpg”、“png”、“tiff”三种格式图像;
(8) 灰度:以何种方式处理数据集图片,包括“gray”和“color”两种类型;
(9) 数据格式:Raw数据集将被转换的格式,可选“lmdb”和“leveldb”。
2.1.2 创建Processed 类型数据集
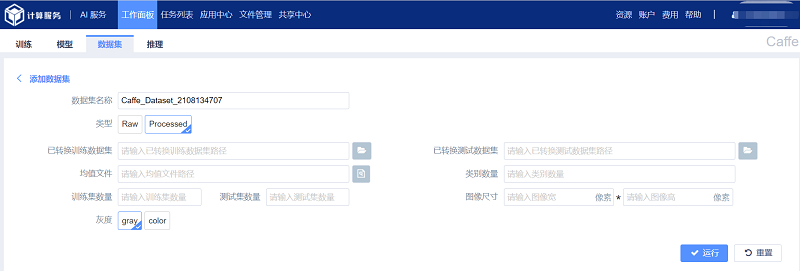
参数设置如下:
(1) 数据集名称:表示创建数据集所使用的名称,不允许重复;
(2) 已转换训练数据集:表示经转换的lmdb 或leveldb 格式训练数据集,点击右侧 选择数据集所在文件夹;
(3) 已转换测试数据集:表示经转换的lmdb 或leveldb 格式验证数据集;
(4) 均值文件:表示图像均值文件,点击右侧 按钮选择均值文件;
(5) 类别数量:表示数据集所涵盖类别的总数;
(6) 训练集数量:训练集中的样本总数;
(7) 测试集数量:验证集中的样本总数;
(8) 图像尺寸:数据集中图像的宽度和高度;
(9) 灰度:数据集中图像的类型,包括“gray”和“color”两种类型;
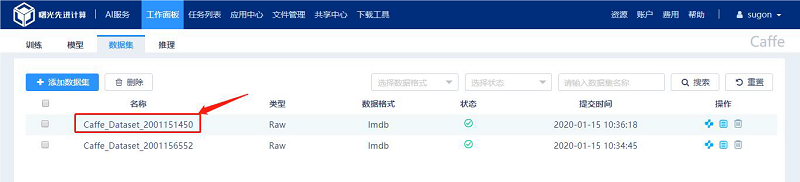
2.1.3 查看数据集详细信息
在Caffe 数据集列表页面,点击“名称”列下对应的数据集名称即可查看详细信息,如图所示:
2.2 Caffe模型
数据集创建成功后,用户可针对其设置适配的模型求解器和网络。
1、点击“添加模型”进入“添加模型求解器”页面,如图所示。
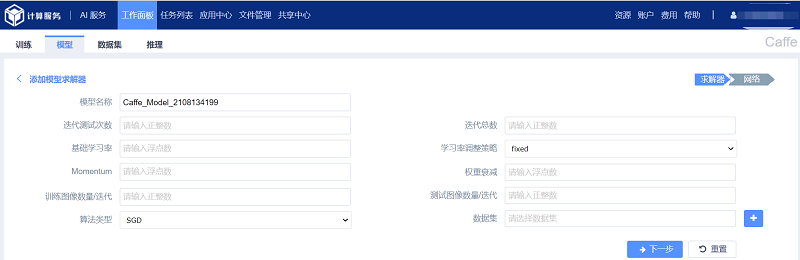
模型求解器中相关选项说明:
(1) 模型名称:模型所使用的名称,不允许重复;
(2) 迭代测试次数:表示每一次测试的轮数;
(3) 迭代总数:表示训练迭代的最大次数;
(4) 基础学习率:即通常意义的base lr;
(5) 学习率调整策略:表示lr 的变化函数,默认为fixed(固定的);
(6) Momentum:学习率动量,越大学习率调整越快;
(7) 权重衰减:loss正则化中,权重部分需要乘以的;
(8) 训练图像数量/迭代:表示在对训练集训练时的batchsize 大小;
(9) 测试图像数量/迭代:表示在对交叉验证集训练时的batchsize 大小;
(10) 算法类型:优化权重的算法,默认为SGD(随机梯度下降);
(11) 数据集:传入2.1节中生成的数据集;当学习率调整策略不为“fix”时,需要额外给定一些参数。
(12) Gamma:表示学习率变化指数(Lr Policy 为step、exp、inv、sigmoid 时需要填写);
(13) Step Size:表示学习率变化频率(Lr Policy 为step、sigmoid 时需要填写);
(14) Power:表示调节学习速率所需参数(Lr Policy 为inv、poly 时需要填写)。
2、点击“下一步”进入“添加模型网络”页面,选择一种网络后,点击“完成”按钮,完成网络的创建。如图所示。
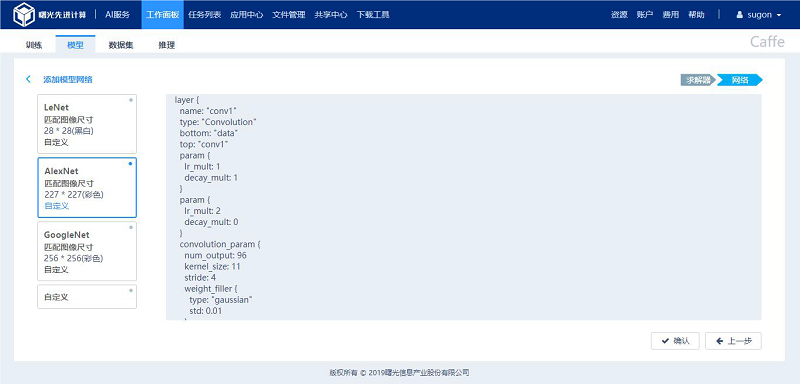
2.3 Caffe训练任务
Caffe 训练任务管理页面显示已经创建过的训练任务。点击"添加训练"按钮,进入下图界面。

(1)训练名称:本次训练的名称,不允许重复。
(2)模型调整(可选):待加载的模型类型,支持“caffeemodel”、“solverstate”。点击 ,选择待加载模型。本选项代表对已训练模型的进一步调整。
(3)CPU数量/DCU数量:训练时使用的资源。
(4)模型:选择在2.2小节中创建的模型。
(5)框架版本:使用的caffe版本。
(6)资源分组:选择要使用的队列。
(7)内存:内存
(8)超时限制:任务被强制中止的时间阈值。
2.4 Caffe推理任务
2.4.1 创建推理任务
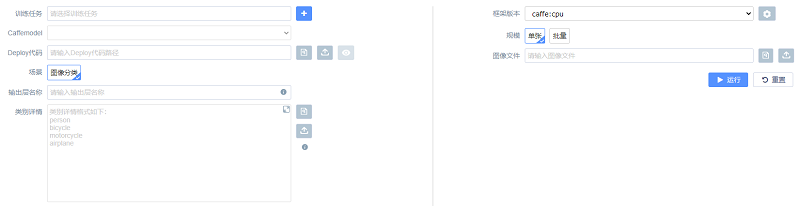
相关选项说明:
(1) 训练任务:选择已完成的训练任务。
(2) Caffemodel:选择训练任务中保存的caffemodel,用以推理。
(3) Deploy 代码:用于推理的网络结构(当使用LeNet、AlexNet、GoogleNet 等三种预置网络训练模型时,会为用户生成相应的Deploy 代码)。
(4) 场景:只支持“图像分类”。
(5) 输出层名称:Deploy 代码中输出层的名称。
(6) 类别详情:用于将推理输出映射为具有实际意义的类别信息。(类别顺序需和创建数据集使用的标签文件保持一致)
(7) 规模:推理针对的图像规模,“单张”或“批量”。
(8) 图像文件:图像或图像所在文件夹的路径。
2.4.2 查看推理结果
推理结果页根据待推理图像的规模不同,分为“单张”和“批量”结果页,如下图所示。
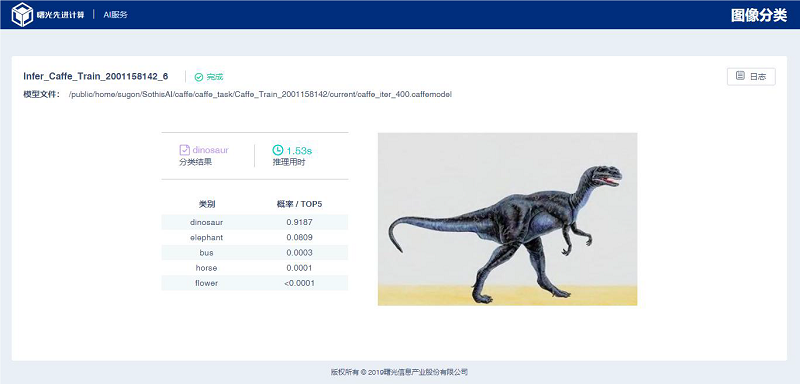
“图像分类推理结果(单张)”页面上半部分展示:任务名称、状态、caffemodel 的存储路径等信息,并提供查看推理日志的功能。
页面中部展示:推理耗时,概率前5 的类别名称及对应的概率。
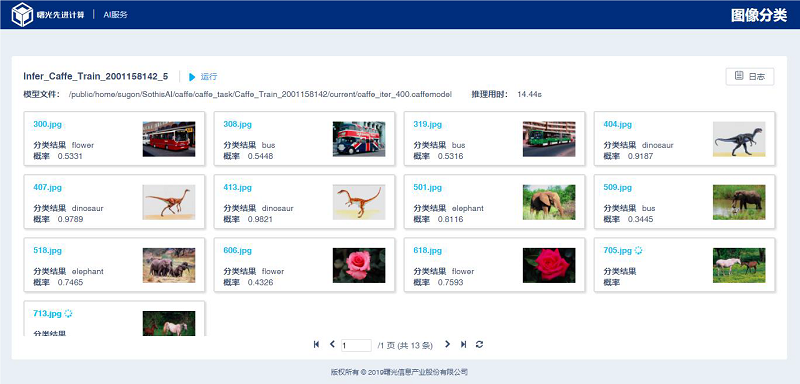
“图像分类推理结果(批量)”页面上半部分展示:任务名称、状态、caffemodel 的存储路径和推理用时等信息,并提供查看推理日志的功能。
页面中部展示:概率最大的类别名称及对应的概率。
3 PyTorch深度学习框架
进入曙光智算平台页面,下拉查看“我的服务”,选中“智能计算服务”,点击“PyTorch”按钮,可以进入PyTorch 的任务管理页面。Pytorch深度学习框架主要有训练和推理任务。


3.1 PyTorch训练任务
训练任务的提交方式支持分布式提交、非分布式提交两种提交方式。
3.1.1 提交分布式任务
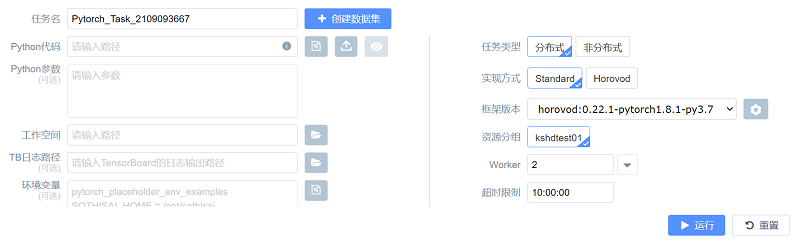
如图所示,创建分布式PyTorch 训练任务时的所需参数包括:
(1) 任务名:表示该任务的名称且不允许重复;
(2) Python 代码:表示训练所需要的python 程序的路径地址,支持手动输入、集群文件选取、和本地文件上传等三种输入方式,可以点击“预览”按钮预览选中的python 程序(参考1.1.1.2-1.1.1.4节);
(3) Python 参数:表示python 代码所需要的参数;(选填)
(4) 工作空间:表示python 程序执行时所在的工作目录,可以通过右边的文件夹浏览按钮选择工作空间的地址;
(5) 框架版本:表示用来进行训练的PyTorch 镜像版本;
(6) TB日志路径:表示用于TensorBoard 的日志文件输出目录,可以通过右边的文件夹浏览按钮选择生成日志所在的文件夹;(选填)
(7) 环境变量:表示训练过程中所需要的环境变量,可以通过右边的文件浏览按钮、文件上传按钮进行环境变量文件的集群选取和本地上传;(选填)
(8) 任务类型:表示训练任务的提交方式,提交分布式任务选中“分布式”;
(9) 资源分组:表示任务使用的队列名称;
(10) 实现方式:分布式任务的两种实现框架,支持“Standard”和“Horovod”;
(11) Worker:表示节点的数量,单机“Worker”后面的箭头可以对单个Worker 作资源配置;
(12) CPU 数量:表示一个Worker 占用的CPU 数量;
(13) GPU 数量:表示一个Worker 占用的GPU 数量;
(14) 内存:表示一个Worker 占用的内存大小;
(15) 超时限制:该任务被强制中止的时间阈值。
输入相关参数,点击“运行”按钮进入训练任务的详情页面。
3.1.2 提交非分布式任务
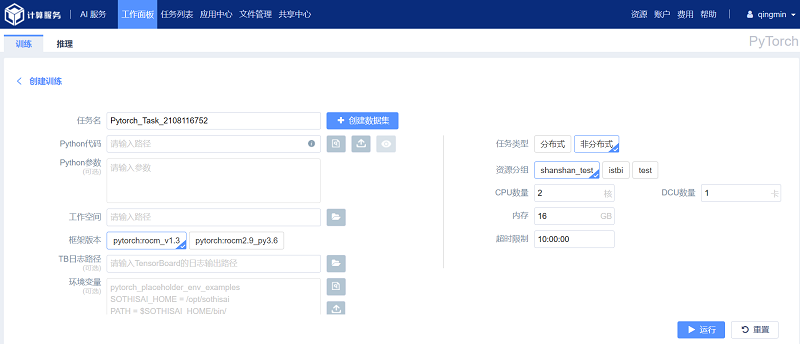
如图所示,创建非分布式PyTorch 训练任务提交相对简单,大部分参数与分布式任务完全相同,请参照3.1.1章节。不同参数包括:
(1) 任务类型:表示训练任务的提交方式,提交非分布式任务选中“非分布式”;
(2) 资源分组:表示训练任务使用的资源分组(默认以GPU 型号作为分组);
(3) CPU数量:表示训练任务占用的CPU 数量;
(4) GPU数量:表示训练任务占用的GPU 数量;
(5) 内存:表示训练任务占用的内存大小;
(6) 超时限制:任务强行中止的时长阈值。
输入相关参数,点击“运行”按钮进入训练任务的详情页面。
3.1.3 SSH 访问容器
点击运行状态下实例对应行的“SSH”按钮,打开新的标签页,通过WebShell 访问该实例对应的容器。
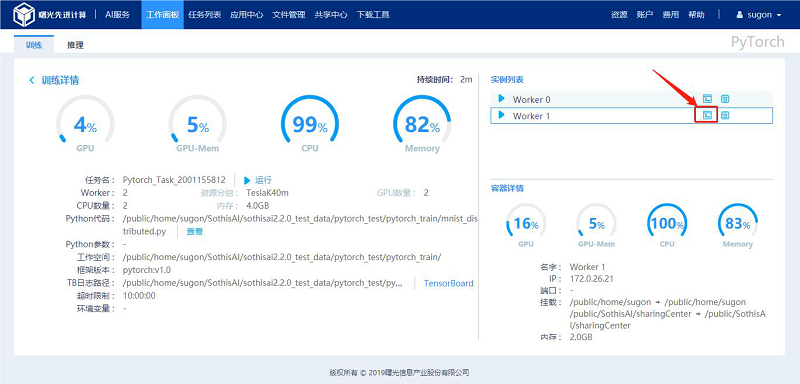
3.1.4 查看容器日志
点击实例对应行的“日志”按钮,查看该实例的容器日志。

3.2 PyTorch推理任务
3.2.1 创建推理任务
创建PyTorch 推理任务有以下两个入口:
(1) 如图对于已完成的PyTorch 训练任务可以点击对应行的“推理”按钮进行推理任务创建页面;
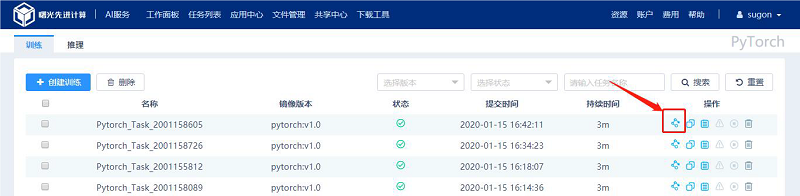
(2) 如图所示,点击“推理”标签页按钮进入推理任务创建页面。
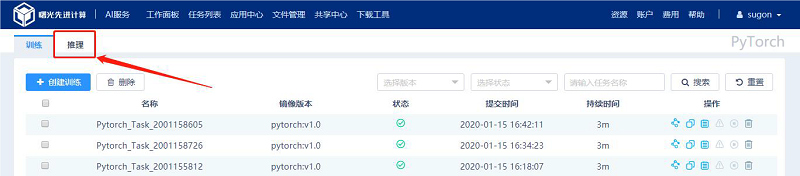
如图所示,创建PyTorch 推理任务时的所需参数包括:
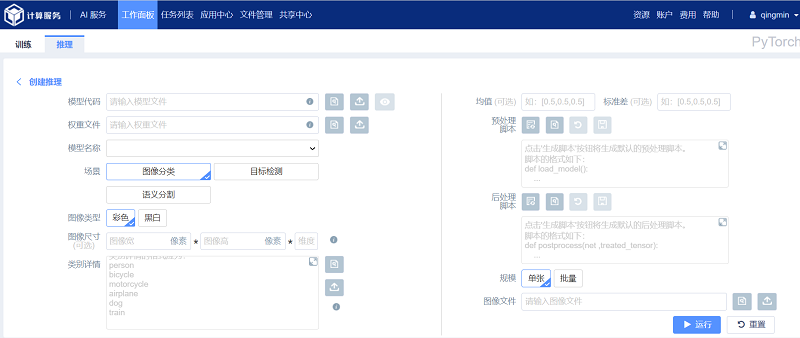
(1) 模型代码:表示定义模型结构的Python 代码,一般保存在训练代码中,支持手动输入、集群文件选取和本地文件上传三种输入方式,可以点击“预览”按钮预览选中的python 程序;
(2) 权重文件:表示保存训练结果的权重文件,通常为.pt、.pth 或者.tar 文件,支持手动输入、集群文件选取和本地文件上传三种输入方式;
(3) 模型名称:表示从模型代码中定位到的模型的类名;
(4) 场景:表示推理场景(目前PyTorch支持图像分类、目标检测和语义分割);
(5) 图像类型:表示模型输入的图像类型,支持彩色或黑白(灰度);
(6) 图像尺寸:表示模型输入层需要的图像尺寸(选填);
(7) 类别详情:用于将推理输出映射为具有实际意义的类别信息,支持手动输入、集群文件选取和本地文件上传三种输入方式;
(8) 均值:表示模型输入前对图像进行归一化处理(和训练时用的均值保持一致会有较好的推理结果)(选填);
(9) 方差:表示模型输入前对图像进行归一化处理(和训练时用的方差保持一致会有较好的推理结果)(选填);
(10) 预处理脚本:对推理图片进行的预处理操作,支持“生成脚本”、“浏览文件”、“撤销”、“保存脚本”、“全屏显示脚本”和自定义修改等操作;
(11) 后处理脚本:对推理后的图片进行后处理操作,支持“生成脚本”、“浏览文件”、“撤销”、“保存脚本”、“全屏显示脚本”和自定义修改等操作;
(12) 规模:表示待推理的图像规模,有“单张”和“批量”两种模式;
(13) 图像文件:图像路径或图像所在文件夹的路径,支持手动输入、集群文件选取和本地文件上传三种输入方式输入相关参数,点击“运行”按钮进入推理任务的详情页面。
3.2.1.1 生成脚本模板
当填写完模型代码、权重文件、模型名称、图像尺寸(选填)、类别详情、均值(选填)和方差(选填)后,可以点击“生成脚本”按钮生成默认的预处理或者后处理脚本模板,用户有自定义需求亦可在脚本内容中进行编写。
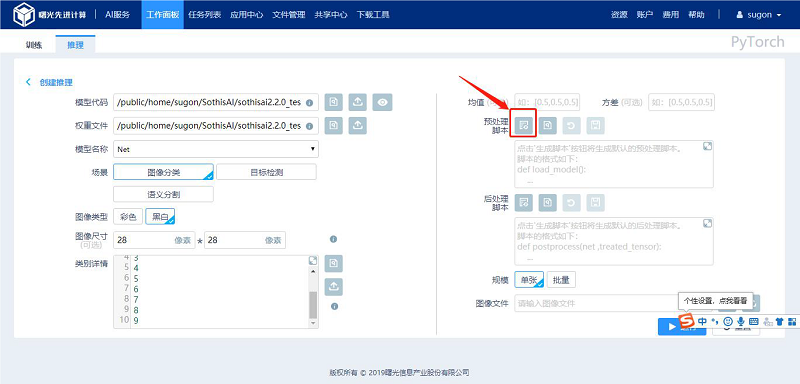
3.2.1.2 浏览文件
以“预处理脚本”为例:
点击“浏览文件”按钮弹出文件选择器,在文件选择器中选中需要使用预处理脚本文件“process.py”,点击“确认”按钮完成文件选取。
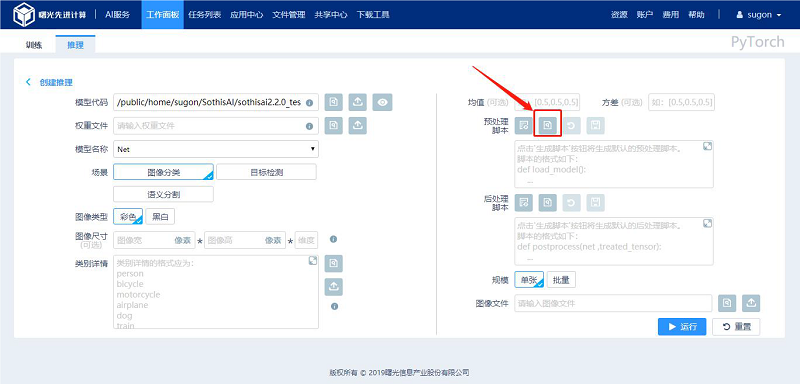
3.2.1.3 撤销脚本内容
用户在脚本输入框中进行自定义修改,点击输入框上方的“撤销”按钮进行撤销操作,脚本内容回滚到上一次保存时的内容。
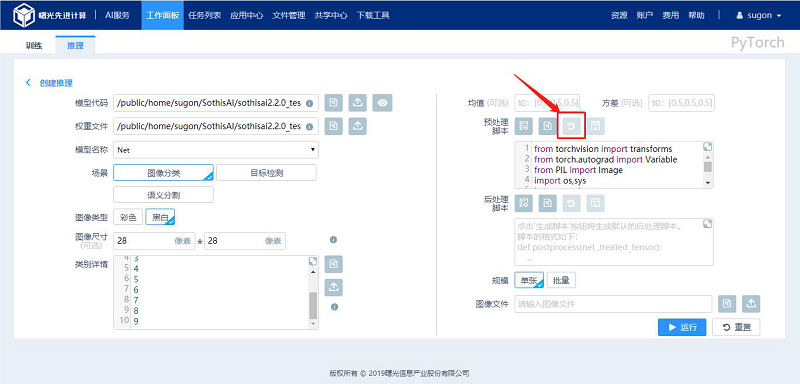
3.2.1.4 保存脚本
用户在脚本输入框中进行自定义修改,点击输入框上方的“保存脚本”按钮进行脚本保存操作。
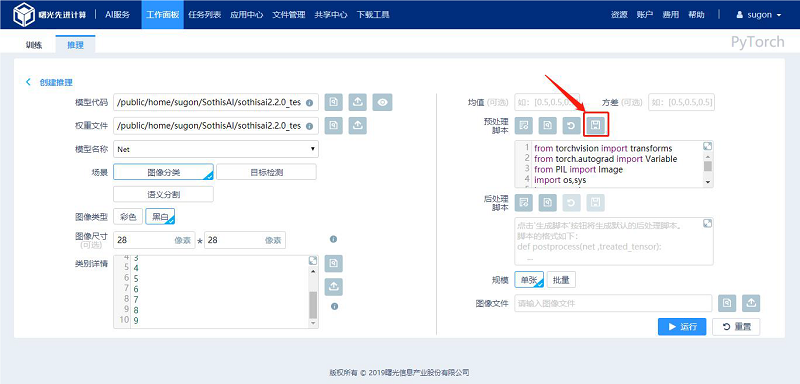
3.2.2 查看推理结果
点击推理创建页的“运行”按钮进入对应场景的推理结果页,也可以点击“任务列表”中对应推理任务行的“查看结果”按钮进行推理结果的查看。
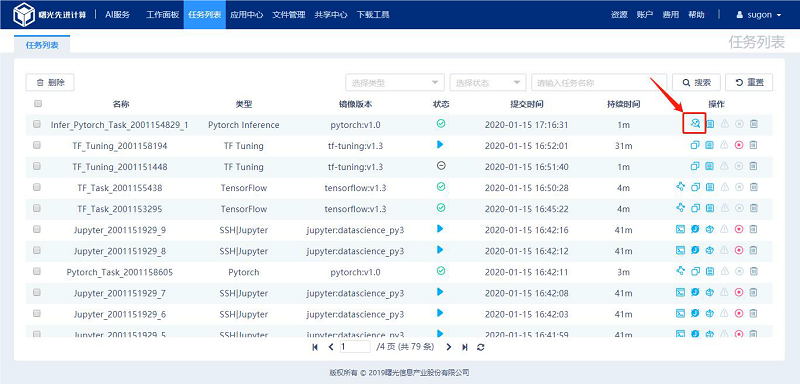
4 SSH/jupyter
进入曙光智算平台页面,下拉查看“我的服务”,点击“智能计算服务”; 选择服务选择平台内置镜像,点击ssh/jupyter。


4.1 创建基础镜像
进入ssh/jupyter订阅镜像后选择对应的参数,容器默认运行时间为10h,最长时间为9999h。
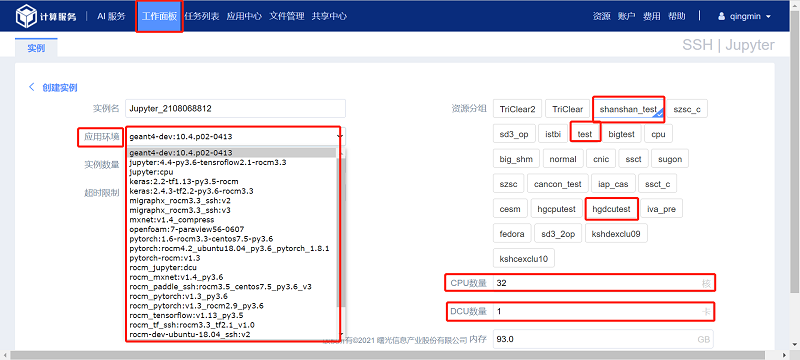
相关选项说明:
(1) 实例名:表示该实例的名称(实例名称为Name+’_’+index,如:Jupyter_2001096479_0)且不允许重复;
(2) 应用环境:选择实例的应用环境;
(3) 资源分组:任务使用的队列名称;
(4) CPU 数量:表示单个实例占用的CPU 数量;
(5) DCU 数量:表示单个实例占用的DCU(GPU) 数量;
(6) 内存:表示单个实例占用的内存大小;
(7) 实例数量:表示本次提交创建的实例个数。
点击运行,创建镜像后,需要等待“状态”属性变为可运行状态(10min左右),然后点击运行。
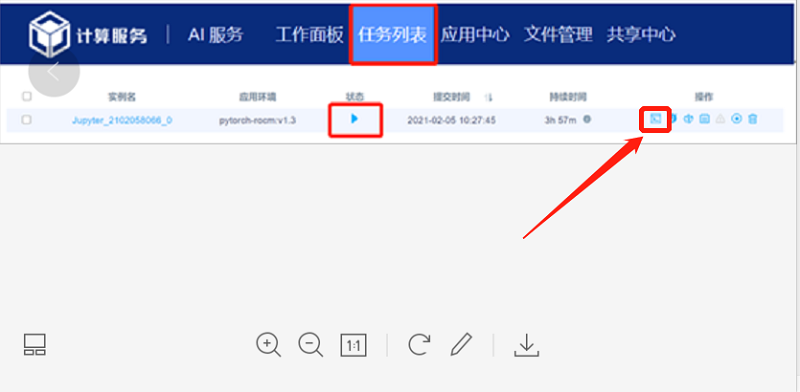

4.2 创建分享镜像
进入曙光智算平台页面,下拉查看“我的服务”,点击“智能计算服务”; 选择平台内置镜像,点击ssh/jupyter
4.3.1 选择分享镜像
选择任务栏“应用中心-选择镜像-克隆 (应用中心镜像可由用户自定义配置,将镜像上传到自己目录下由技术人员添加到镜像仓库)。
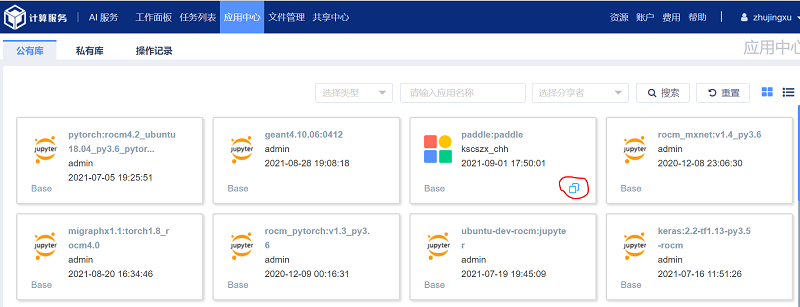
给克隆的镜像命名、标签。注意:“快捷访问”请选择“是”,方便后续操作。
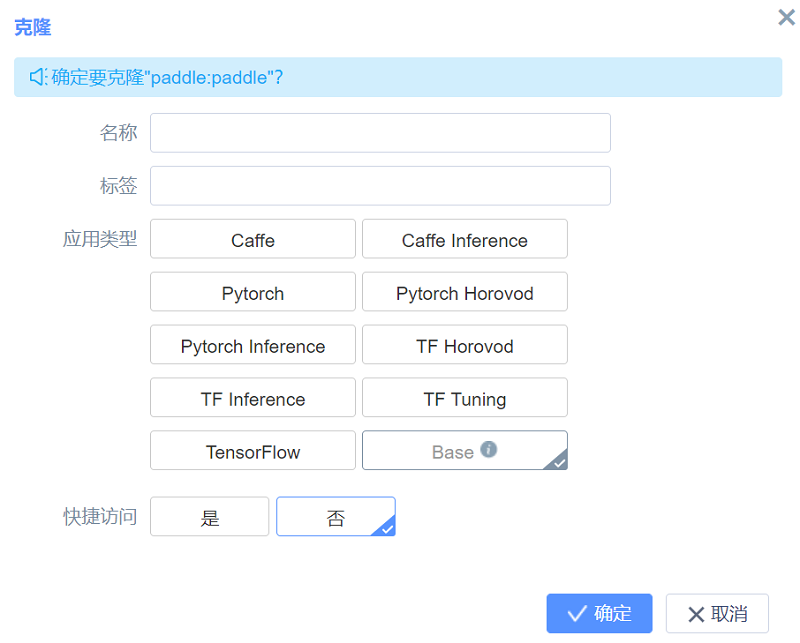
4.3.2 镜像查看
镜像克隆的时长依据镜像使用频率确定,一般不会超过10min。克隆后的镜像文件可在“工作面板”中查看。
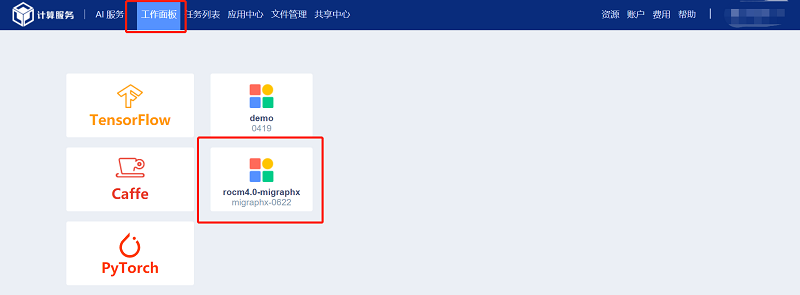
4.3.3 参数设置
点击“工作面板”中克隆的镜像,进入“工作面板”新建实例。

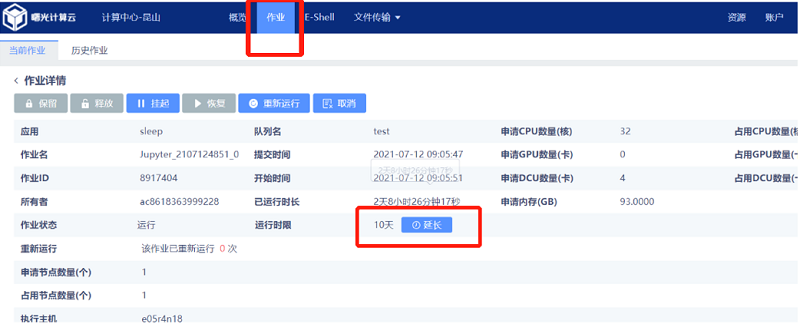
4.3.4 延长时间
在登录主页面任务栏“作业”选项中对docker进行操作,选择“延长”后,原任务时长结束之前剩余时间显示不会发生变化。
4.3 镜像修改
1) 镜像修改定制化需要连接外网,因此需要添加代理(请联系对应工程师申请proxy代理账号)。然后在~/.bashrc中添加以下内容,或者编辑一个shell文件添加以下内容后在容器内执行脚本。
export http_proxy='http://username:password@10.15.150.2:3000'
export https_proxy='http://username:password@10.15.150.2:3000'
export ftp_proxy='http://username:password@10.15.150.2:3000'
2) 下面示例以基础版torch-1.6-rocm-3.3为base创建一个gpt3的环境。需求的扩展包如下:nltk,numpy,pandas,sentencepiece,boto3,regex,torchtqdm,jieba,pybind11。以基础镜像启动torch-1.6-rocm-3.3的实例,同4.1。
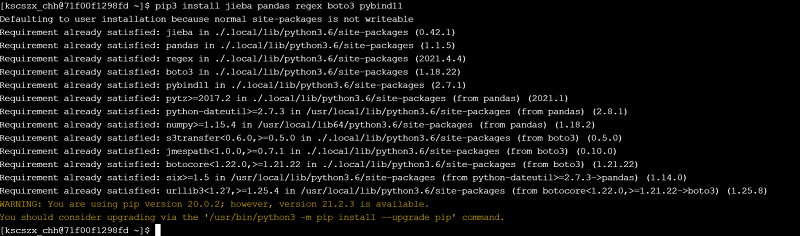
点击ssh标签进入容器后,执行pip3 install jieba pandas regex boto3 ypbind11如下图所示(该图结果为我已经安装过后的):
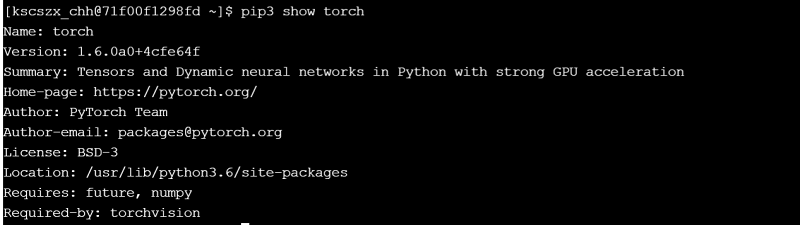
正常安装的扩展包目录为/public/home/username/.local/lib/python3.6/site-packages/,但是容器内site-packages为/usr/lib/python3.6/site-packages下(可以通过pip3 show torch查看,如下图所示)。造成此情况的原因在于:进入镜像后的默认python依然为登陆节点中的python,在6.2小节中提到了处理这种情况的方法之一。下文将介绍将登陆节点python安装包转移至镜像内的方法。
为了固话出来的镜像是任何人都可以用的,所以需要将个人目录下的site-packages里面的扩展包目录拷贝至容器内部。执行:
sudo cp ~/.local/python3.6/site-packages/jieba /usr/lib/python3.6/site-packages/
sudo cp ~/.local/python3.6/site-packages/pandas /usr/lib/python3.6/site-packages/
sudo cp ~/.local/python3.6/site-packages/regex /usr/lib/python3.6/site-packages/
sudo cp ~/.local/python3.6/site-packages/boto3 /usr/lib/python3.6/site-packages/
sudo cp ~/.local/python3.6/site-packages/pybind11 /usr/lib/python3.6/site-packages/
sudo cp ~/.local/python3.6/site-packages/nltk /usr/lib/python3.6/site-packages/
sudo cp ~/.local/python3.6/site-packages/sentencepeice /usr/lib/python3.6/site-packages/
sudo cp ~/.local/python3.6/site-packages/tqdm /usr/lib/python3.6/site-packages/
执行完毕之后,此容器里面就实际存在了这些扩展包,而不是启动容器时候挂载的个人目录有这些包,然后就可以进行镜像固话及分享操作,可以分享给全体或者同组成员了。
4.4 镜像固化
点击“操作”属性中第三个按钮进行固化,然后在弹出框点击“固化”。固化后的镜像可在“工作面板”查看。
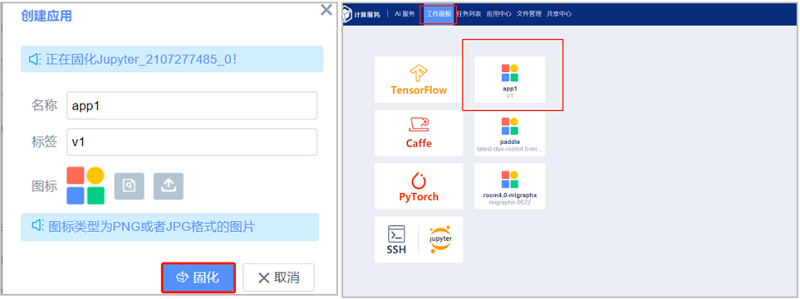
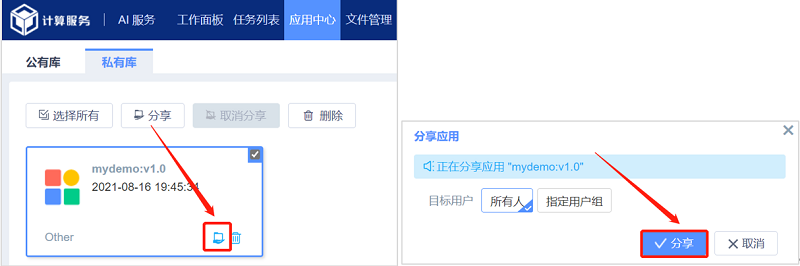
4.5 镜像分享
在个人账户的“私有库”找到固化镜像,点击“分享”按钮,分享给目标用户。目标用户可以选择所有人或者指定用户组。分享后的镜像可以在应用中心的“共有库”查找。
5 以PaddlePaddle为例使用SSH/Jupyter
PaddlePaddle是百度推出的人工智能框架平台,对标谷歌的Tensorflow、Facebook的Pytorch等。一般来说,使用SSH/Jupyter方式(第4小节)是可以直接在配置好环境的镜像内进行代码编写、程序运行的。但是,PaddlePaddle的镜像使用方法相对更复杂,故本小节以PaddlePaddle的镜像使用为例,进一步介绍SSH/Jupyter这一SothisAl方式。
PaddlePaddle在镜像加载前需要登陆E-Shell并配置Conda环境、虚拟环境。
5.1 配置Conda环境
点击首页的E-Shell登陆Login节点,下载Miniconda3安装包,并安装。
下载安装包
wget https://repo.anaconda.com/miniconda/Miniconda3-py37_4.9.2-Linux-x86_64.sh -i https://pypi.tuna.tsinghua.edu.cn/simple/
提高安装包权限
chmod +x Miniconda3-py37_4.9.2-Linux-x86_64.sh
创建新目录并安装
mkdir -p ~/miniconda3/
bash Miniconda3-py37_4.9.2-Linux-x86_64.sh -b -f -p "~/miniconda3/"
删除安装包
rm -rf Miniconda3-py37_4.9.2-Linux-x86_64.sh
初始化Conda环境。
~/miniconda3/bin/conda init
source ~/.bashrc
5.2 创建虚拟环境
使用Conda命令创建虚拟环境,并在虚拟环境下安装ROCM的PaddlePaddle。
创建虚拟环境
conda create -n paddleClas python=3.7
conda activate paddleClas
安装PaddlePaddle 此处使用的whl包可以从 https://www.paddlepaddle.org.cn/whl/rocm/stable.whl 下载。
pip install -U paddlepaddle_rocm-0.0.0-cp37-cp37m-linux_x86_64.whl
下载PaddleClas并安装依赖包(方便后续使用) 如果出现git失败的情况,可以直接从github下载并上传(注意路径)
git clone https://github.com/PaddlePaddle/PaddleClas.git
cd PaddleClas && pip install -r requirements.txt
5.3 在镜像内使用PaddlePaddle
1、在首页“我的服务”一栏选择“智能计算服务”。

2、新页面顶栏选择应用中心。

3、在公有库中从如下两个镜像中挑选一个,并克隆。

4、名称、标签自行设置,将“快捷访问”设置为“是”,方便后续操作。
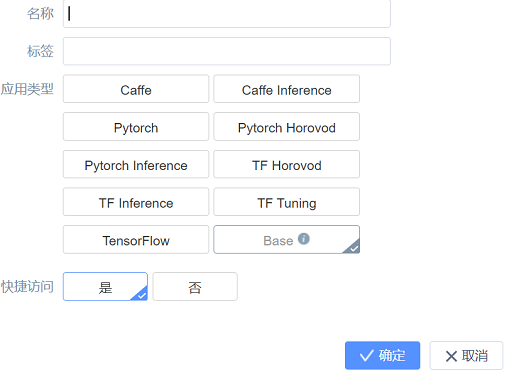
5、在“应用中心”的“操作记录”下有克隆镜像的历史操作。可以观察镜像克隆的进度。

6、注意,一般在10min以内(频繁使用的镜像更快),镜像会克隆成功 。此后,镜像会被加入您的“私有库”。通过点击“工作面板”中的新图标,即可进入镜像实例创建。

7、点击创建实例,并按需分配相关资源,点击运行。
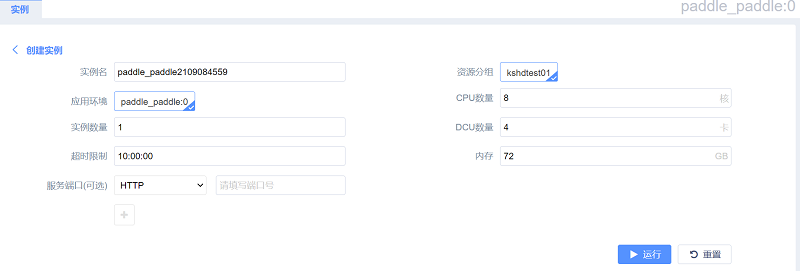
8、实例进入部署状态,此时一般需要等待10min以内。待实例状态进入运行后 ,在右侧点击SSH 进入WebShell。

9、进入WebShell后的正常状态如下图所示。如果不正常,可以重新创建实例(第7步)。

10、注意,如果是root用户,则相关环境变量是正确的。如果不是root用户,请检查以下环境变量配置是否正确。
source /opt/rh/devtoolset-7/enable # devtoolset-7
export PATH=/opt/cmake-3.16/bin:${PATH} # cmake
export PATH=/opt/rocm/bin:${PATH} # rocm
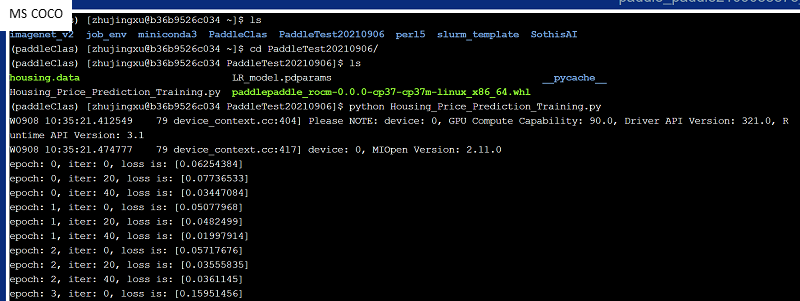
11、输入“conda activate paddleClas”激活之前配置的虚拟环境。本文在/public/software/apps/DeepLearning/Benchmark/PaddlePaddle/housing提供了测试文件(housing.data和Housing_Price_Prediction_Training.py),您可以将其移动至您的个人地址,并输入“python Housing_Price_Prediction_Training.py”运行,程序在最后会生成“LR_model.pdparams”权重文件。(注意地址) 如下图所示。

6 以MMCV为例固化自己的镜像
MMCV是商汤公司贡献的人工智能算法框架OpenMMLab中的视觉底层框架。以它为底层,OpenMMLab还有很多知名的开源项目,例如:MMClassification、MMDetection等。本文将以MMCV-1.3.8环境的搭建为例,介绍镜像固化的具体操作。 本文镜像的主要使用环境如下表所示。

6.1 创建基础镜像
对照4.1小节创建自己的镜像,选择下图所示的应用环境。

开始创建镜像后,一般需要等待10min左右,可以通过SSH 方式进入镜像。进入镜像后正常界面如下图所示(WebShell),如果不正常可通过短暂等待10min,或重新创建镜像。极端情况下请联系管理员查看节点状态。
在搭建环境前,请先申请proxy权限,参考4.3小节。
6.2 搭建环境
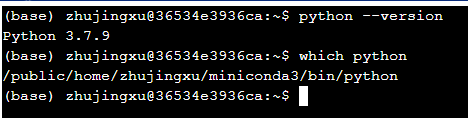
笔者的个人节点已经安装了Miniconda3和Python3.7。在WebShell内键入python –version和which python,如下图所示。可以发现当前默认环境依然是登陆节点环境,而并非是镜像内环境。
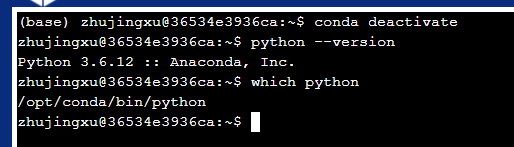
为了进入镜像环境,输入sudo -i获取权限,并输入conda deactivate,再查看Python版本和地址,可以发现已经进入镜像,如下图。(不同镜像Python地址可能有别,但只要不是“public/home/用户名”中的Python,则都是镜像内Python)
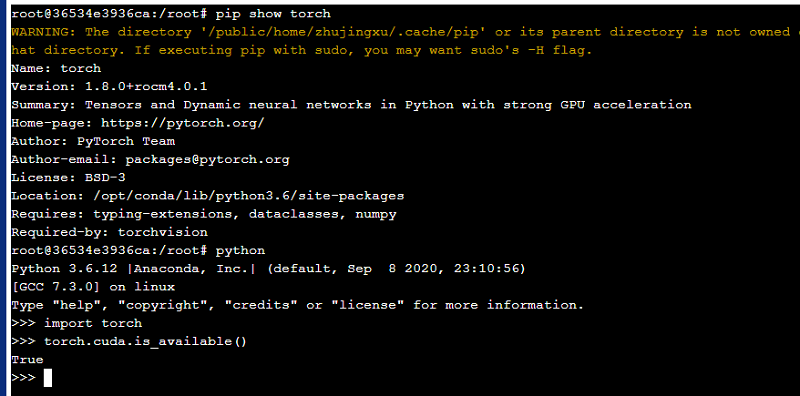
确认自己进入镜像环境后,则可以开始根据自己的需要,修改环境。 第一步,输入pip uninstall torch,卸载Pytorch1.9。然后在网址https://download.pytorch.org/whl/rocm4.0.1/torch_stable.html选择Pytorch1.8版本,并上传至个人目录。或直接从(public/software/apps/DeepLearning/whl/rocm-4.0.1/torch-1.8.0+rocm4.0.1-cp36-cp36m-linux_x86_64.whl)获取Pytorch1.8版本的whl包。使用“pip install 文件路径”安装Pytorch。此时查看Pytorch的详细信息,并进入Python调用Pytorch,可以发现:Pytorch被安装到镜像内,并且cuda可以使用。如下图所示。
第二步,安装对应版本的torchvision。键入“pip install torchvision==0.9.0 -i https://pypi.tuna.tsinghua.edu.cn/simple/”即可(记得退出Python)。
第三步,安装rocm4.0.1版本的mmcv1.3.8。whl包在 “public/software/apps/DeepLearning/whl/rocm-4.0.1/mmcv_full-1.3.8-cp36-cp36m-linux_x86_64.whl”。
通过上述操作,mmcv的环境搭建完毕。为了验证环境的可用性,可以从(public/test/mmcv_test.py)获取测试用文件“mmcv_test.py”,并测试环境可用性。如下图所示。
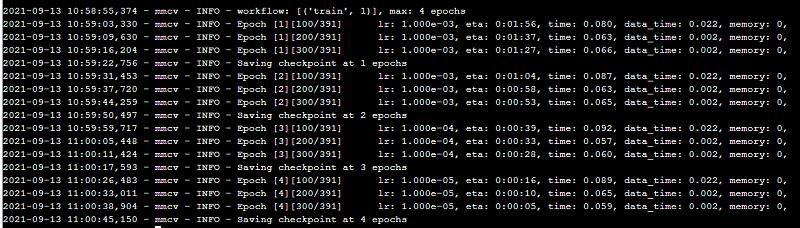
环境可用。
6.3 镜像固化
在任务列表中点击“固化”按钮 ,可以固化修改后的镜像,以便下次使用。可以参考4.4小节。

镜像固化一般耗时在10min以内,固化后的镜像可以在“私有库”推送,可以在“工作面板”快速启动。注意:通过新镜像创建实例可能较慢,需要等待一小段时间。
另外,昆山集群提供了MMCV环境的镜像,在“公有库”中选择如下镜像即可。
7 Notebook
进入曙光智算平台页面,在首页(概览)下拉查看“我的服务”,点击“智能计算服务”;选择Notebook创建任务。这里共有三种开发工具:Jupyter、VS code和RStudio。
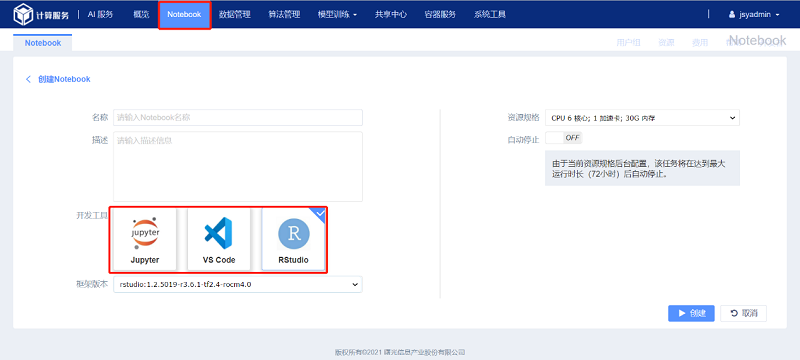
7.1 Jupyter
进入Jupyter模块,如图所示:
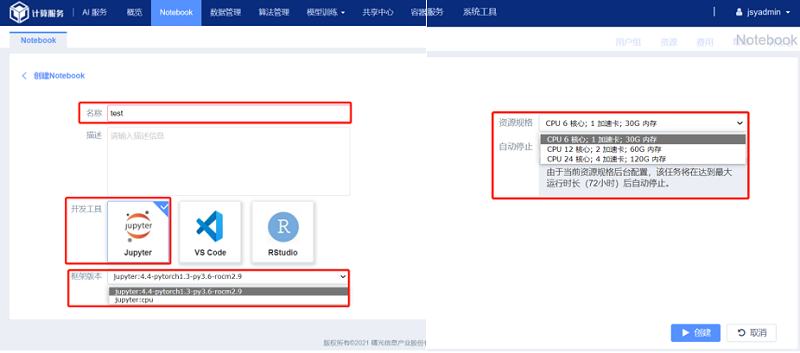
名称:自定义命名创建的任务;
(2) 开发工具:Notebook共提供三种开发工具:Jupyter、VS code和RStudio;
(3) 框架版本:Jupyter共提供CPU和GPU两种框架;
(4) 资源规格:Jupyter共提供三种不同配置的资源供选择。
--------------------------------测试用例 - 简单矩阵乘法-----------------------------------
1、输出pytorch的版本以及是否有GPU;
import torch
import time
from torch import autograd
torch.cuda.is_available()
print(torch.__version__)

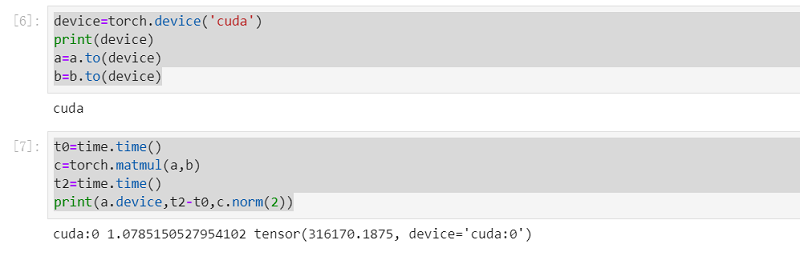
2、创建tensor及三次计算的耗时; 其中第一次是CPU计算,第二次和第三次是GPU计算。第二次比第一次时间明显减少,因为用了gpu加速;第三次比第二次同样少很多,应该是cpu存在缓存。
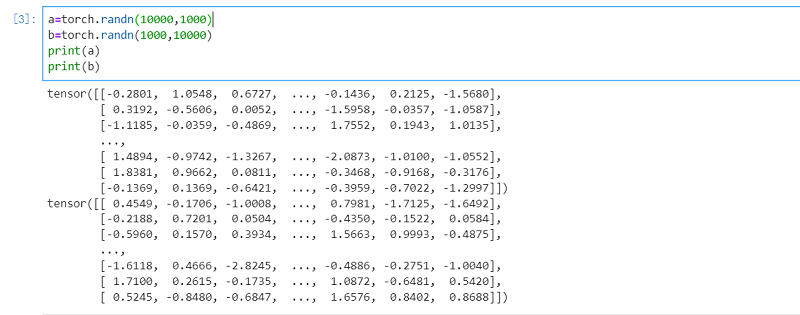
a=torch.randn(10000,1000)
b=torch.randn(1000,10000)
print(a)
print(b)
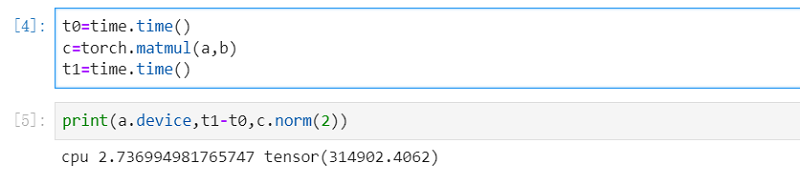
t0=time.time()
c=torch.matmul(a,b)
t1=time.time()
print(a.device,t1-t0,c.norm(2))
device=torch.device('cuda')
print(device)
a=a.to(device)
b=b.to(device)
t0=time.time()
c=torch.matmul(a,b)
t2=time.time()
print(a.device,t2-t0,c.norm(2))
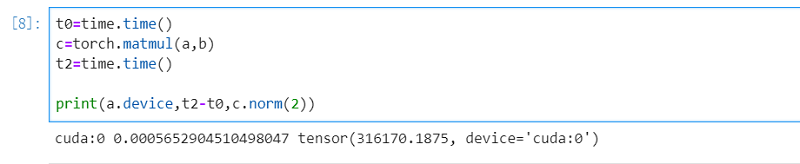
t0=time.time()
c=torch.matmul(a,b)
t2=time.time()
print(a.device,t2-t0,c.norm(2))
7.2 VS code
进入VS code模块,如图所示:
(1) 名称:自定义命名创建的任务;
(2) 开发工具:Notebook共提供三种开发工具:Jupyter、VS code和RStudio;
(3) 框架版本:VS code共提供pytorch和tensorflow两种框架;
(4) 资源规格:VS code共提供三种不同配置的资源供选择。
-------------------------------------测试示例- 简单矩阵乘法----------------------------------
待补充
7.3 RStudio
进入RStudio模块,如图所示:

(1) 名称:自定义命名创建的任务;
(2) 开发工具:RStudio共提供三种开发工具:Jupyter、VS code和RStudio;
(3) 框架版本:RStudio共提供pytorch和tensorflow两种框架;
(4) 资源规格:RStudio共提供三种不同配置的资源供选择。
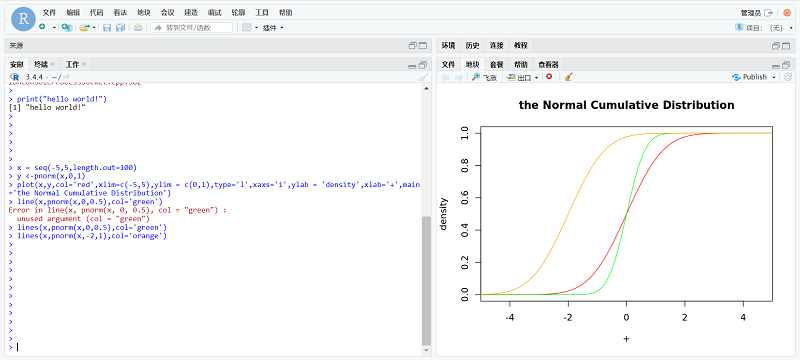
--------------------------------测试示例 - 正太分布画图-----------------------------------
画出随机变量X服从 N(0,0.5),N(0,1), N(0,2)累计分布曲线。
正态分布的累计分布函数是:
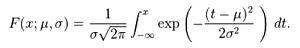
累积分布函数的定义(cumulative distribution function):对连续函数,所有小于等于a的值,其 出现概率的和。F(a)=P(x<=a)。
> x = seq(-5,5,length.out=100)
> y <-pnorm(x,0,1)
> plot(x,y,col='red',xlim=c(-5,5),ylim = c(0,1),type='l',xaxs='i',ylab = 'density',xlab='+',main='the Normal Cumulative Distribution')
> line(x,pnorm(x,0,0.5),col='green')
> lines(x,pnorm(x,0,0.5),col='green')
> lines(x,pnorm(x,-2,1),col='orange')
使用方法二:E-Shell方式 Module调用固定模板
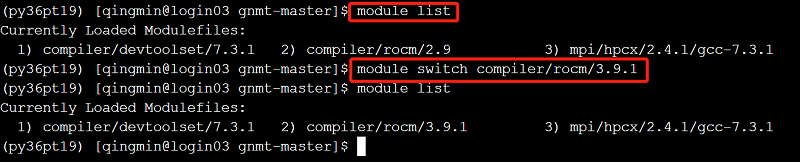
1 切换ROCM版本
ROCM默认版本为rocm-2.9。若需要切换rocm-3.9.1或rocm-4.0.1,版本切换命令如下:
// 方式一
module rm compiler/rocm/2.9
module load compiler/rocm/3.9.1
// 方式二
module switch compiler/rocm/3.9.1
2 加载不同的App的Module
1) 设置某项目的环境变量可以通过module load 命令加载相应环境变量。例如,加载TensorFlow1.15.3。 // 查找已有环境变量
module av
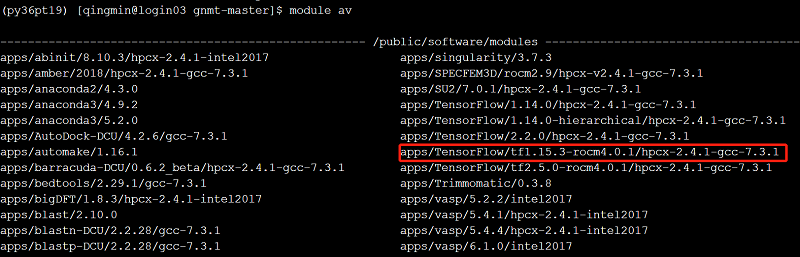
//找到需要添加的环境变量,添加环境变量
module load apps/TensorFlow/tf1.15.3-rocm4.0.1/hpcx-2.4.1-gcc-7.3.1
即加载了TensorFlow1.15.3环境。
2) 查看已经加载上的环境变量:
module list

3 sbatch脚本提交任务
本节以公共目录下的图片分类任务(ImageNet_v2模型)为例进行展示。
(1) 将ImageNet_v2模型从公共目录拷贝到个人目录。
ImageNet_v2路径:/public/software/apps/DeepLearning/Benchmark/PyTorch/
cp -rf /public/software/apps/DeepLearning/Benchmark/PyTorch/imagenet_v2 ./

(2) 编辑脚本,参数设置如下,可选择单节点单卡,单节点多卡,以及多节点多卡运算模式。(此脚本“mpi_slurm.sbatch”在个人目录里的imagenet_v2文件夹中有)



(3) 提交脚本运行。

(4) 生成标准结果输出文件和标准错误输出文件。


使用方法三:E-Shell Conda自定义环境使用
1 MiniConda安装
1) 使用wget下载
wget https://repo.anaconda.com/miniconda/Miniconda3-py37_4.9.2-Linux-x86_64.sh -i https://pypi.tuna.tsinghua.edu.cn/simple/
(或者使用本地sh安装包,路径在:/public/software/apps/DeepLearning/whl/Miniconda/)
2) 添加权限并运行
chmod +x Miniconda3-py37_4.9.2-Linux-x86_64.sh
mkdir -p ~/miniconda3/
bash Miniconda3-py37_4.9.2-Linux-x86_64.sh -b -f -p "~/miniconda3/"
rm -rf Miniconda3-py37_4.9.2-Linux-x86_64.sh
3) 初始化 conda 环境
~/miniconda3/bin/conda init
source ~/.bashrc
2 两种方式自定义PyTorch环境
2.1 本地安装PyTorch-1.7
1) 本地whl所在目录
/public/software/apps/DeepLearning/whl
2) conda创建python3.6环境
conda create -n pytorch_1.7-rocm_3.9.1-custom python=3.6
3) 在conda环境中安装PyTorch1.7
conda activate pytorch_1.7-rocm_3.9.1-custom

pip install /public/software/apps/DeepLearning/whl/rocm-3.9.1/torch-1.7.0a0-cp36-cp36m-linux_x86_64.whl -i https://pypi.tuna.tsinghua.edu.cn/simple/
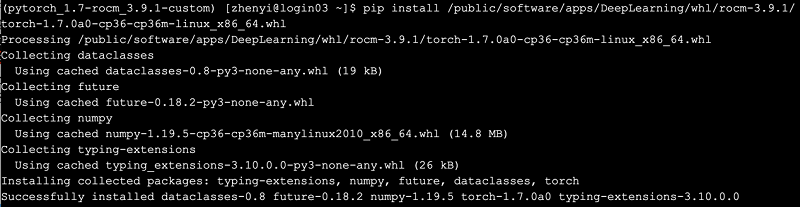
4) 安装依赖包
pip install absl-py six wrapt -i https://pypi.tuna.tsinghua.edu.cn/simple/

5) 安装方式一:自定义安装所需文件包
conda install lmdb=0.9.24 -y
ln -s /public/home/user_name/miniconda3/envs/pytorch_1.7-rocm_4.0.1/lib/liblmdb.so /public/home/user_name/miniconda3/envs/pytorch_1.7-rocm_4.0.1/lib/liblmdb.so.0.0.0
conda install openblas -y
编译opencv:opencv2.4 位于/public/software/apps/DeepLearning/whl/rocm-4.0.1/
cp -r /public/software/apps/DeepLearning/whl/rocm-4.0.1/opencv-2.4.13.6.tar.gz /public/home/user_name/software
tar -zxvf opencv-2.4.13.6.tar.gz
mkdir -p /public/home/user_name/miniconda3/opencv-2.4/
cd opencv-2.4.13.6
mkdir build
cd build
cmake -D CMAKE_BUILD_TYPE=RELEASE -D CMAKE_INSTALL_PREFIX=/public/home/user_name/miniconda3/opencv-2.4 ..
make -j4 && make install
添加环境变量
vi ~/.bashrc
export LD_LIBRARY_PATH=/public/home/user_name/miniconda3/opencv-2.4/lib/:$LD_LIBRARY_PATH
source ~/.bashrc
添加所需软链接
ln -s /public/software/apps/DeepLearning/PyTorch/lib/libglog.so.0 /public/home/user_name/miniconda3/envs/pytorch_1.7-rocm_4.0.1/lib/libglog.so.0
ln -s /public/software/apps/DeepLearning/PyTorch/lib/libgflags.so.2.1 /public/home/user_name/miniconda3/envs/pytorch_1.7-rocm_4.0.1/lib/
6) 安装方法二:加载集群已安装的文件路径
修改~/.bashrc文件,加载集群已安装的PyTorch依赖包,依赖包路径在:/public/software/apps/DeepLearning/PyTorch/
vi ~/.bashrc
将如下变量放进~/.bashrc中:
export SSL_HOME=/public/software/apps/DeepLearning/Libs/openssl-1.1.0j
export OPENBLAS_HOME=/public/software/apps/DeepLearning/PyTorch/openblas-0.3.7-build
export LDMB_HOME=/public/software/apps/DeepLearning/PyTorch/lmdb-0.9.24-build
export OPENCV_HOME=/public/software/apps/DeepLearning/PyTorch/opencv-2.4.13.6-build
export BOOST_HOME=/public/software/mathlib/boost/1.72.0
export PYTORCH_LIB=/public/software/apps/DeepLearning/PyTorch
export LD_LIBRARY_PATH=${SSL_HOME}/lib:$LD_LIBRARY_PATH
export LD_LIBRARY_PATH=${OPENBLAS_HOME}/lib:$LD_LIBRARY_PATH
export LD_LIBRARY_PATH=${LDMB_HOME}/lib:$LD_LIBRARY_PATH
export LD_LIBRARY_PATH=${OPENCV_HOME}/lib:$LD_LIBRARY_PATH
export LD_LIBRARY_PATH=${BOOST_HOME}/lib:$LD_LIBRARY_PATH
export LD_LIBRARY_PATH=${PYTORCH_LIB}/lib:$LD_LIBRARY_PATH
更新系统文件
$ source ~/.bashrc
7) 安装TorchVision,安装whl包位置在目录:
/public/software/apps/DeepLearning/whl/rocm-4.0.1
激活conda环境
conda activate pytorch_1.7-rocm_3.9.1-custom
pip install /public/software/apps/DeepLearning/whl/rocm-4.0.1/torchvision-0.8.0a0+132984f-cp36-cp36m-linux_x86_64.whl
8) 申请并登录计算节点,进行测试
salloc -p kshdtest -N 1 --gres=dcu:4

登录计算节点
ssh e05r4n01
切换rocm编译器版本,删除rocm_2.9,加载rocm_3.9.1
module rm compiler/rocm/2.9
module load compiler/rocm/3.9.1

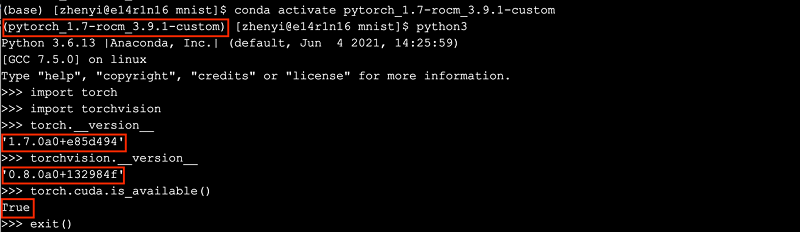
加载conda环境中自定义安装的PyTorch环境,运行python3,检查安装情况
conda activate pytorch_1.7-rocm_3.9.1-custom$ python3
>>> import torch
>>> import torchvision
>>> torch.__version__
>>> torchvision.__version__
>>> torch.cuda.is_available()
9) 如果有提交作业脚本,在slurm脚本中添加配置MIOPEN环境变量
export MIOPEN_DEBUG_DISABLE_FIND_DB=1
export MIOPEN_DEBUG_CONV_WINOGRAD=0
export MIOPEN_DEBUG_CONV_IMPLICIT_GEMM=0
export HSA_USERPTR_FOR_PAGED_MEM=0
export GLOO_SOCKET_IFNAME=ib0,ib1,ib2,ib3
export MIOPEN_SYSTEM_DB_PATH=/temp/pytorch-miopen-2.8
2.2 在线安装PyTorch-1.9
1) 创建环境
conda create -n pytorch_1.9-rocm_4.0.1 python=3.6
conda activate pytorch_1.9-rocm_4.0.1

2) 安装pytorch-1.9和torchvision-0.10.0
pip3 install torch -f https://download.pytorch.org/whl/rocm4.0.1/torch_stable.html -i https://pypi.tuna.tsinghua.edu.cn/simple/
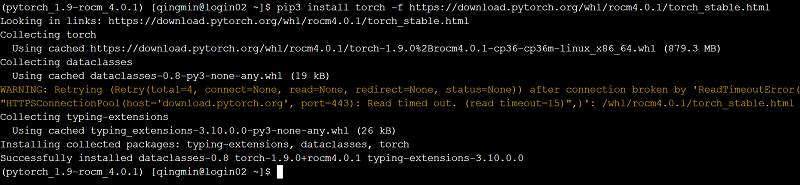
pip3 install ninja -i https://pypi.tuna.tsinghua.edu.cn/simple/

pip3 install 'git+https://github.com/pytorch/vision.git@v0.10.0'
(该文件若无法下载请联系支持人员)
3) 在slurm脚本中添加配置MIOPEN环境变量
export MIOPEN_DEBUG_DISABLE_FIND_DB=1
export MIOPEN_DEBUG_CONV_WINOGRAD=0
export MIOPEN_DEBUG_CONV_IMPLICIT_GEMM=0
export HSA_USERPTR_FOR_PAGED_MEM=0
export GLOO_SOCKET_IFNAME=ib0,ib1,ib2,ib3
export MIOPEN_SYSTEM_DB_PATH=/temp/pytorch-miopen-2.8
4) 在bashrc文件中添加路径
vi ~/.bashrc
export LD_LIBRARY_PATH=/public/home/user_name/miniconda3/bin/../lib/:$LD_LIBRARY_PATH
source ~/.bashrc
5) 测试
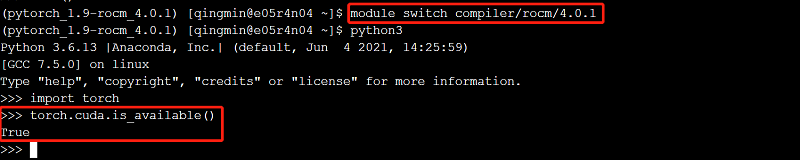
module switch compiler/rocm/4.0.1
conda activate pytorch_1.9-rocm_4.0.1
python3
>>>import torch
>>>torch.cuda.is_available()
True
2.3 本地安装PyTorch-1.9
1) 创建python3.6环境
conda create -n pytorch_1.9-rocm-4.0.1 python=3.6
2) 安装pytroch-1.9,本地wheel包在/public/software/apps/DeepLearning/whl/rocm-4.0.1/目录下。
conda activate pytorch_1.9-rocm-4.0.1
pip install /public/software/apps/DeepLearning/whl/rocm-4.0.1/torch-1.9.0+rocm4.0.1-cp36-cp36m-linux_x86_64.whl -i https://pypi.tuna.tsinghua.edu.cn/simple/
将公共目录中torchvision包拷贝到自定义的conda环境中的site-package中(注意修改拷贝目的地路径的用户名)
cp -r /public/software/apps/DeepLearning/whl/rocm-4.0.1/torchvision-0.10-pytorch1.9-rocm-4.0.1-py36/torchvision/ /public/home/username/miniconda3/envs/pytorch_1.9-rocm-4.0.1/lib/python3.6/site-packages/
cp -r /public/software/apps/DeepLearning/whl/rocm-4.0.1/torchvision-0.10-pytorch1.9-rocm-4.0.1-py36/torchvision-0.10.0a0+cde7ff0.dist-info/ /public/home/username/miniconda3/envs/pytorch_1.9-rocm-4.0.1/lib/python3.6/site-packages/
安装依赖包:(可以使用清华源)
pip3 install numpy pillow -i https://pypi.tuna.tsinghua.edu.cn/simple/
3) 在slurm脚本中添加配置MIOPEN环境变量
export MIOPEN_DEBUG_DISABLE_FIND_DB=1
export MIOPEN_DEBUG_CONV_WINOGRAD=0
export MIOPEN_DEBUG_CONV_IMPLICIT_GEMM=0
export HSA_USERPTR_FOR_PAGED_MEM=0
export GLOO_SOCKET_IFNAME=ib0,ib1,ib2,ib3
export MIOPEN_SYSTEM_DB_PATH=/temp/pytorch-miopen-2.8
4) 在bashrc文件中添加路径
vi ~/.bashrc
export LD_LIBRARY_PATH=/public/home/user_name/miniconda3/bin/../lib/:$LD_LIBRARY_PATH
source ~/.bashrc